

Introduction
Many exciting applications, such as data encryption and genetic algorithm programs, use randomly generated numbers to make choices. In some (rare) cases, only truly random numbers will do; that makes things complex because programs are based on logic, and the logic they use can generally be reversed. In other words, it is difficult to program a series of logical steps that produces numbers that don’t follow some kind of pattern. One approach for generating truly random numbers is to measure some kind of continuous natural phenomena; for instance, the noise power level in a radio-frequency receiver. The noise power level appears to be random because the power level at any instant in time depends on so many variables, such as cosmic radiation, solar energy, Earth thermal energy, and so forth. For most applications, pseudo-random numbers are sufficient. Pseudo-random numbers follow predictable patterns, but they do so over very long periods. The idea is that you would have to look at a very long (maybe in the billions) string of numbers before you would see a repeat of the pattern.
A conceptually simple way to generate long sequences of pseudo-random numbers is with a linear feedback shift register (lfsr). The tapped elements (the memory slots connected to the circle with the plus inside) are XOR’ed (0 xor 1 = 1; 0 xor 0 = 0; 1 xor 1 = 0) and then placed in the right-most bit slot, pushing all the previous bits one slot to the left. The sequence of 1s and 0s that pop off the left side of the register are the pseudo-random number sequence. The catch is that some tap positions cause the register to short cycle; in other words, some tap positions do not use the register to its greatest capability. A register’s maximum-length sequence will be (2^n – 1) bits long; n is the number of slots in the register. A short cycle in the register has occurred if the register ends up with the same fill that it started with before (2^n – 1) cycles elapse. Any book on spread spectrum communications or error correcting codes is bound to have a table listing tap positions corresponding to maximal length sequences for given LFSR lengths.
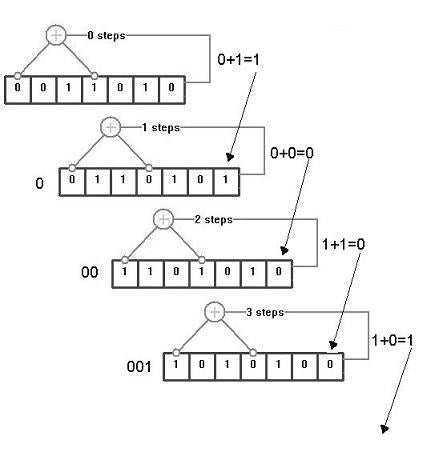
Figure 1: LFSR with an initial fill (0,0,1,1,0,1,0) and taps on elements (0,3)
Overview
Generating pseudo-random numbers is only half the battle if you want to use a particular pseudo-random number sequence in encryption or error-correction codes. The other half is re-generating the same sequence based on some (partial) information that may or may not be provided by the sender. So, how does the sequence generation really work? Believe it or not, the mathematical toolset for sequence generation is fairly simple and most experienced developers have probably already been exposed to it. Decoding an incoming sequence is a bit more involved, but uses the same mathematical techniques combined with extensive decision logic, depending on the application. In the explanation that follows, I have tried to provide some nuts and bolts of the mathematics without too much detail, and then follow it up with several simplistic uses of pseudo-random sequences. If you made it this far, you may be tempted to skip ahead to the samples so I just want to mention that the kind of mathematical background provided in the next section is really the key that unlocks the only entrance to the world of understanding encryption and error-correction codes. Of course, you can find other explanations, and probably much better ones, but you will have to work through this kind of math sometime if you want to begin to understand the nitty-gritty and the gritty-nitty of encryption and error correction codes.
Mathematical Background
LFSR operations can be simulated mathematically by using a construct of abstract algebra called a finite field. Field, set, ring, and group are all just fancy mathematical names for grouping numbers together based on their properties. The “field” part of the name is because operations on numbers in this particular “grouping” (i.e. plus, minus, multiply, or divide) result in numbers that belong to the same “grouping.” For a counter-example, take the set of positive integer numbers, take any two numbers and add them and the result is also a positive integer number; so far, so good. Subtracting one positive integer from another ( i.e. 2 – 7 = -5) could generate a result that is not a positive integer, so positive integers are not a field. For fields, this is never the case. Addition, subtraction, multiplication, and division always result in a member of the same field. By this reasoning, real numbers are a field because addition, subtraction, multiplication, and division on real numbers always result in more real numbers…let’s just forget about division by zero for the moment. The “finite” part of the name is because, unlike the real numbers field that has infinite members, finite fields have only limited members. A finite field is often called a Galois (pronounced Gal-wah) field after a mathematician who did early research on their properties.
So, the field GF(2) actually has two members: 0 and 1. GF(2) is of special interest because polynomial multiplication and division over this field mimic the operations of a LFSR. Before jumping into polynomial multiplication and division and modulus operations, let’s go over some basics. Addition for GF(2) is implemented as modulo-2 addition, otherwise known as exclusive-or. The following table shows the results of addition and multiplication operations on members of GF(2). Just for future reference: These operations apply equally well to the polynomial representation of any LFSR.
|
+
|
0
|
1
|
x
|
0
|
1
|
|
|
0
|
0
|
1
|
0
|
0
|
0
|
|
|
1
|
1
|
0
|
1
|
0
|
1
|
For the following discussion, keep in mind that x7 is actually x raised to the seventh power, sometimes written as x^7. The same is true for all the “x” terms, skipping the “^” exponent character is just a shorthand way of writing the same thing. Multiplication with exponents works in a similar way to normal exponent multiplication; so, using x as the base of the exponent, the following examples show the exponent rules and the notation used throughout this article: x^2 * x^5 = x^(2+5) = x^7 = x7, also x^5 / x^2 = x^(5-2) = x^3 = x3.
The output bit stream from a LFSR can be described by long division of polynomials as follows: A(x) = output bit stream = P(x) / Q(x) where Q(x) is called the generator polynomial, also known as the characteristic polynomial. For the LFSR in the picture below, the generator polynomial would be: x5 = x2 + 1.
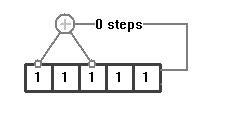
The generator polynomial is determined from the location of the tap positions on the LFSR. The polynomial is fifth order because there are five memory slots. Slots 0 and 2 have taps; this leads to: x^2 + x^0 = x^2 + 1 = x2 + 1. For the 5th order LFSR above every generator polynomial of greater than 4th order can be reduced to a polynomial consisting of terms less than or equal to 4th order. Because of the way addition and subtraction work on GF(2), the x5 term can move to the other side of the equals sign without any sign change like it would in normal subtraction, so the equation x5 = x2 + 1 is equivalent to x5 + x2 + 1 = 0.
The numerator P(x) in the expression A(x) = P(x) / Q(x) has to do with the content of the LFSR’s memory slots and the number of times the LFSR has been stepped. For the LFSR shown in the picture above, the numerator polynomial after 13 steps is x13 = x4 + x3 + x2. Starting from that point, each step of the LFSR corresponds to multiplication (by GF(2) rules) of x. The following table lists the numerator polynomials for the 31 possible fills of this LFSR:
| Step | Current Fill | Numerator Polynomial = (x^step) modulo the generator polynomial (x5 + x2 + 1) |
| 0 | 00001 | 1 |
| 1 | 00010 | x |
| 2 | 00100 | x2 |
| 3 | 01001 | x3 |
| 4 | 10010 | x4 |
| 5 | 00101 | x5 = x2 + 1 |
| 6 | 01011 | x6 = x3 +x |
| 7 | 10110 | x7 = x4 + x2 |
| 8 | 01100 | x8 = x3 + x2 + 1 |
| 9 | 11001 | x9 = x4 + x3 + x |
| 10 | 10011 | x10 = x4 + 1 |
| 11 | 00111 | x11 = x2 + x + 1 |
| 12 | 01111 | x12 = x3 + x2 + x |
| 13 | 11111 | x13 = x4 + x3 + x2 |
| 14 | 11110 | x14 = x4 + x3 + x2 + 1 |
| 15 | 11100 | x15 = x4 + x3 + x2 + 1 |
| 16 | 11000 | x16 = x4 + x3 + x + 1 |
| 17 | 10001 | x17 = x4 + x + 1 |
| 18 | 00011 | x18 = x + 1 |
| 19 | 00110 | x19 = x2 + x |
| 20 | 01101 | x20 = x3 + x2 |
| 21 | 11011 | x21 = x4 + x3 |
| 22 | 10111 | x22 = x4 + x2 + 1 |
| 23 | 01110 | x23 = x3 + x2 + x + 1 |
| 24 | 11101 | x24 = x4 + x3 + x2 + x |
| 25 | 11010 | x25 = x4 + x3 + 1 |
| 26 | 10101 | x26 = x4 + x2 + x + 1 |
| 27 | 01010 | x27 = x3 + x + 1 |
| 28 | 10100 | x28 = x4 + x2 + x |
| 29 | 01000 | x29 = x3 + 1 |
| 30 | 10000 | x30 = x4 + x |
| 31 | 00001 | x31 = 1 |
The numerator polynomials in the right-hand column of the table above are found by multiplying “x” times the polynomial corresponding to the previous fill. For example, arbitrarily starting with the fill in row 25, which corresponds to:
| x25 | = x * (x4 + x3 + x2 + x) | this is x times x24—the polynomial for the previous fill |
| = x*x4 + x*x3 + x*x2 + x*x | using xi * xj = x(i+j) | |
| = x5 + x4 +x3 + x2 | multiplying everything out | |
| = (x2 + 1) + x4 + x3 + x2 | using x5 = x2 + 1 | |
| = x4 + x3 + x2 + x2 + 1 | grouping like terms together | |
| = x4 + x3 + 1 | using x2 + x2 = 0 |
and dividing the numerator polynomial (x4 + x3 + 1) by the denominator polynomial (x5 + x2 + 1), we get the actual output bit stream of the LFSR. This division is easily, but painfully, carried out through long division as follows:
1/x+1/x2+1/x4+1/x6+1/x11+1/x14+1/x16+1/x17+1/x20+1/x21+1/x22
____________________________________________________________
x5 + x2 + 1 /x4 + x3 + 1 = x25
x4 + x + 1/x
---------------------
x3 + x + 1 + 1/x
x3 + 1 + + 1/x2
----------------
x + 1/x + 1/x2
x + 1/x2 + 1/x4
---------------
1/x + 1/x4 etc...
The quotient of the above operation is actually the output from the LFSR. Starting with the first term, 1/x and 1/x2 mean that the first two bits are 1s. There is no 1/x3 term, so the third bit is a 0; next comes a 1 due to the 1/x4 term, then 0 due to a missing 1/x5 term, and so on. So, the code corresponding to the quotient is:
[1101010000100101100111….]
Comparing this to the actual bitstream obtained from stepping the register (starting from x25):
[11010100001…] They are identical. So, the GF(2) finite field is a mathematical tool that can be used to simulate an LFSR, and it is relatively easy to implement in hardware (or software) by using logic gates and delay flip flops.
Implementation
The sample implementation below actually uses a 24-bit linear feedback shift register (LFSR class) and a singleton class for consistency. The 24-bit property means that it will cycle 16,777,215 times before repeating. The singleton property is so that the generator will only be initialized once for a given computer program. Also, a critical section has been added for thread safety. The code exposes a simple function with the following prototype:
double GenerateNumber(void);
The first time it gets called, the singleton will get initialized (more on that in a moment) and a number will be generated. One question is: How do you initialize the LFSR? The easiest approach is to step the shift register a certain number of times. Of course, we don’t want the same number popping out of the GenerateNumber function every time it gets initialized. That would look really bad, so we really are faced with a random number generation problem to initialize our random number generator. So, what one-time operation can we do that will give us a number that we can use to step the register a random number of times? It could be the seconds in the current minute; at least for a while that might appear fairly random. Another idea is to calculate a long series for a specific length of time, and then take the last few digits. This approach might be good because it would depend on the processor speed and system loading. At least, different systems would generate different numbers. The approach I settled on for the sample project was to take the output of GetTickCount() and put some of the bits (if they are set) into the fill of the shift register, so that I get some change with time, and then step the register based on the process identifier, so that I get some change for each and every initialization of the generator. This combination seems to be a nicely randomized initialization sequence.
Simple Genetic Algorithm Sample
Genetic algorithms operate on codes (or solutions) in a way that is similar to genetic mutation in biological systems. The basic similarities are: 1) the best solutions thrive through many generations of mutation and 2) the best solutions become obvious in the presence of a diverse population. Diversity of the population is where the random number generator can help.
To explore these concepts in a problem-solving scenario, consider the following family riddle. There are two families, each with 3 boys and 3 girls all under age 10 and no twins (none are the same age). In one family, the youngest girl was just born, so her age is 0. The rest are between 1 and 9. In each family, the sum of the boys ages equals the sum of the girls’ ages and the sum of the squares of the boys’ ages equals the sum of the squares of the girls’ ages. Also, the total of all the ages adds up to 60. The puzzle is to figure out the age of each child.
You can easily solve the puzzle by brute force in a short time with any modern personal computer (by short time, I mean anywhere from 20 seconds to 4 minutes, depending on the speed of your computer.) And, you are guaranteed a solution! You simply set up some loops with a check for the solution by trying every possible combination of ages. However, you may recognize that even 1 minute is an eternity for a modern desktop computer and it really should not take so long to solve a simple little riddle like this one. A better approach: genetic algorithms. Similar to other heuristic search algorithms, it is a way of not trying every possible solution but still being relatively sure you have found the correct answer (when it converges). Unfortunately, genetic algorithms don’t always converge. One reason for not converging is that the random number generator is not introducing enough diversity into the search; without enough diversity and population size, the algorithm may get stuck near a local optima.
So, the basic approach is to develop a refined scoring system and then build up a population of families by mutating and removing. You can implement the mutation and removal any way you want, but in the example application I used a simple loop that does all the scoring. The loop sorts the potential solutions (families), then gets rid of the “bad” families, then mutates the remaining families. Thresholds are built in so that a certain percentage of the “best” families are kept and cloned and the clones are mutated. This approach keeps the best families around for further competition in case one of the families is part of the solution and the rest of the solution has so far eluded the algorithm.
Genetic Algorithm snippet:
void GeneticOperator::FindSolution(int seconds)
{
m_startTicks = GetTickCount();
DWORD milliSeconds = seconds * 1000;
DWORD halfMS = (DWORD)(0.50 + milliSeconds/2.0);
int score;
m_foundSol = false;
m_count = 0;
m_best_score = 1024;
// So, we start with 2 sets of families, m_pop1 and m_pop2. The
// basic idea is that a solution will consist of a family from
// m_pop1 and a family from m_pop2. So, we want to compare all
// the families in m_pop1 to all the families in m_pop2, then do
// some population control so that we avoid dealing with massive
// loops.
while (!m_foundSol){
for (int i=0;i<m_pop1.GetSize();i++){
for (int j=0;j<m_pop2.GetSize();j++){
m_count++;
// check to see if we have a solution; if so, we're done
if (m_puzzle.IsSolution(m_pop1.GetData()[i],
m_pop2.GetData()[j]))
{
m_foundSol = true;
m_faSol.Copy(m_pop1.GetData()[i]);
m_fbSol.Copy(m_pop2.GetData()[j]);
return;
}
else
{
// not a solution, so evaluate it
score = m_puzzle.EvaluateFamilies(
m_pop1.GetData()[i],m_pop2.GetData()[j]);
m_best_score = (score < m_best_score) ?
score : m_best_score;
// We're looking for the best matching score; in
// other words, out of all the possible families
// that this (i) family is compared to, we want the
// score from the one that is closest to being the
// other half of the solution.
if (score < m_pop1.GetData()[i].getScore())
m_pop1.GetData()[i].setScore(score);
if (score < m_pop2.GetData()[j].getScore())
m_pop2.GetData()[j].setScore(score);
}
}
// check to see if we have exceeded the time limit
if ((GetTickCount() - m_startTicks) > milliSeconds)
{
return;
}
}
SortPopulation(m_pop1);
SortPopulation(m_pop2);
DecimatePopulation(m_pop1);
DecimatePopulation(m_pop2);
MutatePopulation(m_pop1); // these two use the random
// number generator
MutatePopulation(m_pop2);
}
}
Simple Encryption Sample
The basis of encryption is adding information to a coded sequence in such a way that decoding is easy for authorized users and difficult (hopefully impossible) for unauthorized users. Nothing new so far; so, how can we accomplish this with a pseudo-random number generator? The approach in the sample program is to take the input data bit by bit and combine it with the bits of the input data in a simple way that will be very difficult for unauthorized users to figure out. For each bit of input data, we add 24 bits of output (1s or 0s) from the LFSR with one catch: If the input bit is a 1, then the first time we find a 1 in the LFSR output bit stream, we flip it to 0 (zero), and vice-versa for a 0-input bit. Then, the modified output data is broken into 4-bit pieces and each 4-bit piece is used to assign a character value from an array of characters.
Given some encrypted data, we can simply use the same array of characters to reconstruct the 4-bit pieces, then the original output stream. Once we have the output stream, it is very simple to scan it for bits the have been flipped, and the flipped bits are the original input data. Simple.
The goal here is to demonstrate a simplistic encryption scheme for explanation purposes that will encrypt any data and produce text (ASCII) type output. Of course, this approach does not produce encrypted data that is acceptably secure unless you only want to avoid other users from reading your data. If you want to keep hackers out of your data, this approach will only slow them down momentarily.
The following code sample is just an excerpt from the project:
void Encryptor::EncryptString(std::string& input,
std::string& output)
{
char c, val;
UINT32 i, j, k;
unsigned char x;
ArrayContainer<char> fill;
ArrayContainer<UINT32> taps;
ArrayContainer<unsigned char> xout;
bool flipped;
for (i=0;i<4;i++) taps.AddElement(CryptParams::initTaps[i]);
for (i=0;i<24;i++) fill.AddElement((char)
CryptParams::initFill[i]);
LFSR r;
r.CreateLFSR(CryptParams::regLength,taps,fill);
//
// Okay, we don't want the output stream to look similar from
// one execution to the next, so we have to encode some
// randomness into the output stream. We can accomplish this
// by stepping the register a random number of times.
//
UINT32 randomCycles = (UINT32)(16 * GenerateNumber());
// This character will be encoded as the last character of the
// output stream...just trying to be sneaky
char randomChar = CryptParams::charMap[randomCycles];
for (i=0;i<(randomCycles*7);i++) r.Step(val);
UINT32 length = input.length();
//
// for each character in the string
//
for (i = 0; i < length; i++){
c = input.c_str()[i];
//
// for each bit in this character
//
for (j = 0; j < 8; j++){
x = 1 & (c>>j);
flipped = false;
//
// For each bit output from the shift register up to the
// chip (spreading) length, we output a bit to the
// output stream of 1s and 0s, the only catch is that
// the first time we see a bit that does not match our
// input bit, we flip it. So, we are spitting out lots
// of 1s and 0s that have nothing to do with the
// information we are trying to hide. So, if someone wants
// to crack this code, they will have to figure out
// (and be able to predict) the sequence (in order to know
// where the bit flip took place).
//
for (k = 0; k < CryptParams::chipLength; k++){
r.Step(val);
if (!flipped)
{
if (x == 1)
{
if (val == 0)
{
val = 1;
flipped = true;
}
}
else
{
if (val == 1)
{
val = 0;
flipped = true;
}
}
}
xout.AddElement((unsigned char)val);
}
}
}
UINT32 size = xout.GetSize();
unsigned char * xptr = xout.GetData();
output = "";
//
// Okay, we have a nice output stream of 1s and 0s; now we
// will break down the stream into 4-bit blocks (i.e. these are
// numbers between 0 and 15) and output the corresponding
// character from the character map in the namespace above.
//
for (i = 0; i < size; i += 4){
x = xptr[i];
x |= (xptr[i+1]<<1);
x |= (xptr[i+2]<<2);
x |= (xptr[i+3]<<3);
output += CryptParams::charMap[x];
}
//
// Add the random character to the end of the string so that
// we will know how to un-do the randomness
//
output += randomChar;
}
void Encryptor::DecryptString(std::string& input,
std::string& output)
{
char c, val;
UINT32 i, j, k;
unsigned char x;
ArrayContainer<char> fill;
ArrayContainer<UINT32> taps;
ArrayContainer<unsigned char> xout;
LFSR r;
for (i=0;i<4;i++) taps.AddElement(CryptParams::initTaps[i]);
for (i=0;i<24;i++) fill.AddElement((char)CryptParams::initFill[i]);
//
// Setting up the exact same shift register used in the
// encryption routine.
//
r.CreateLFSR(CryptParams::regLength,taps,fill);
// Remember, the last character is the random cycles encoded.
UINT32 length = input.length() - 1;
//
// Intercepting the last character of the encrypted data and
// interpreting it as the number of random cycles used for
// initializing the shift register.
//
char randomChar = input.c_str()[length];
UINT32 randomCycles = findChar(randomChar);
for (i=0;i<(randomCycles*7);i++) r.Step(val);
//
// Now, for each character in the encrypted text we pull out
// four bits (1s or 0s) and add it to the bit stream. Basically
// we are reproducing the bit stream created by the encryption
// scheme.
//
for (i = 0; i < length; i++){
j = findChar(input.c_str()[i]);
x = (1 & j);
xout.AddElement(x);
x = (1 & (j>>1));
xout.AddElement(x);
x = (1 & (j>>2));
xout.AddElement(x);
x = (1 & (j>>3));
xout.AddElement(x);
}
UINT32 size = xout.GetSize();
UINT32 nChars = size / (CryptParams::chipLength * 8);
k = 0;
unsigned char * xptr = xout.GetData();
bool flipped;
UINT32 bit;
output = "";
//
// Now that we have re-created the bit stream, we just need to
// look for the bits that are flipped use those bits to create
// the original string of characters.
//
for (i = 0; i < nChars; i++){
c = 0;
for (bit = 0; bit < 8; bit++){
flipped = false;
for (j = 0; j < CryptParams::chipLength; j++){
r.Step(val);
if (!flipped)
{
if ((val == 1) && (xptr[k] == 0))
{
// the real bit must have been a zero
flipped = true;
}
else if ((val == 0) && (xptr[k] == 1))
{
c |= (1<<bit);
flipped = true;
}
}
k++;
}
}
output += c;
}
}
Sample Project
The sample project is just a dialog with three options. The first option demonstrates the generation of random numbers, the second option uses the random number generator to solve a puzzle using a simple genetic algorithm technique, and the third option uses the number generator to encrypt text data in a very simplistic way.
The sample code was not written to be the most optimized, professional code. The main purpose was to demonstrate the concepts in the article. So, the sample software has NOT been through any rigorous testing procedure that would be used for professional code. Also, there are so many different approaches to encryption and genetic algorithms; this is just one simple approach intended to illustrate the use of pseudo-random numbers.
Enjoy.